Les concepts primitifs d’un ordinateur
Pour transmettre un savoir à quelqu’un, si on veut être compris on s’exprime en utilisant des concepts qu’il ou elle connaît déjà. Il faut faire de même pour instruire un ordinateur.
Depuis le cours précédent, notre objectif est d’enseigner à l’ordinateur la syntaxe abstraite du Canevas de l’empathie. Nous avons préparé pour lui une description détaillée de celle-ci, mais il sera incapable de la comprendre s’il n’a aucune notion de ce que sont les booléens, les entiers, les réels et les chaînes de caractères. Dans cet article, nous allons voir que ces concepts lui sont familiers.
Les ordinateurs physiques
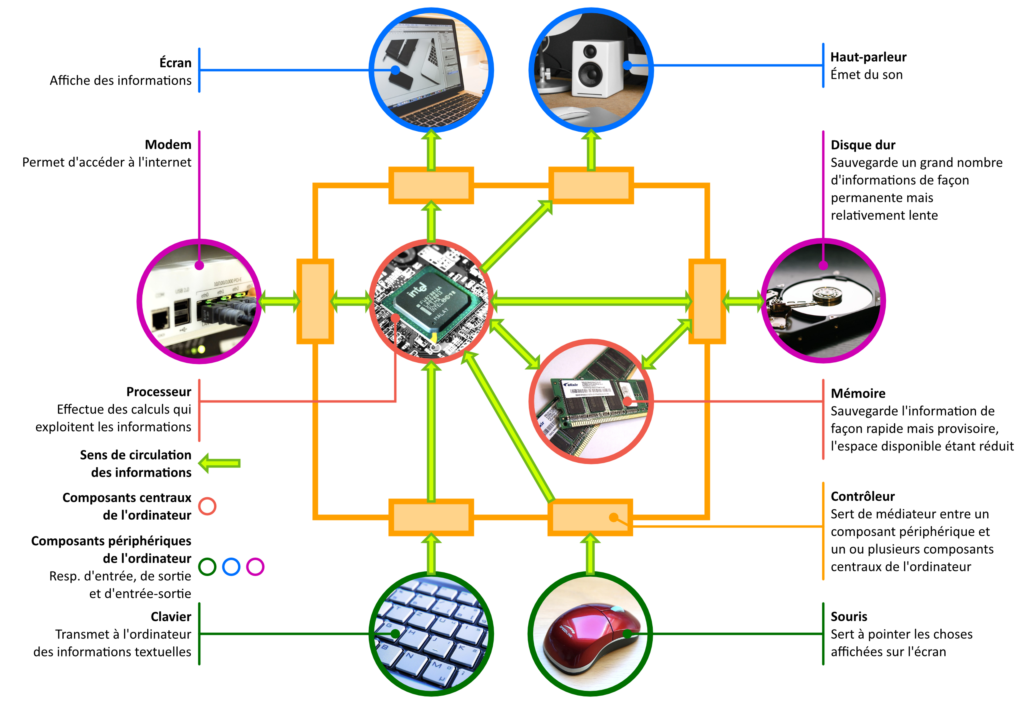

La fonction principale d’un ordinateur est d’exploiter les informations qui lui parviennent par ses composants périphériques d’entrée (figure 1). Par exemple : le texte tapé au clavier (figure 1), le déplacement de la souris (figure 1), le son capté par le microphone, la vidéo que la webcaméra est en train de filmer.
Ces informations affluent vers le processeur (figure 1), qui les prend en charge.
Le processeur ne décide pas toutefois par lui-même de ce qu’il va en faire : il se contente de suivre les instructions laissées par des programmeurs à l’intérieur des logiciels, des applications et des programmes (tous ces termes sont synonymes) que l’utilisateur choisit de lancer (en cliquant par exemple sur leurs icônes).
Le programme en train d’être exécuté par le processeur — et qui en a donc momentanément le contrôle — va forcément, tôt ou tard (sinon il n’aurait aucune utilité), lui faire transmettre ces informations, ou de nouvelles informations calculées à partir d’elles, à un ou plusieurs composants périphériques de sortie ou d’entrée-sortie comme, par exemple, un écran (figure 1), un haut-parleur (figure 1), une imprimante, un modem (figure 1) ou un disque dur (figure 1), pour que celui-ci les affiche (figure 1), les traduise sous forme de son (figure 1), les imprime dans un document, les partage sur l’internet (figure 1), ou les sauvegarde en lieu sûr (figure 1).
La différence entre un composant périphérique d’entrée et un composant périphérique de sortie est la suivante : un composant périphérique d’entrée est pour le processeur — et, par là même, pour le programme qu’il est en train d’exécuter — un composant source d’informations (figure 1), tandis qu’un composant périphérique de sortie est, pour lui, un composant récepteur d’informations (figure 1). Un composant périphérique d’entrée-sortie est un composant périphérique à la fois d’entrée et de sortie, c.-à-d. un composant périphérique qui lui fournit des informations mais à qui il en envoie aussi (figure 1).
Comme on peut le voir sur la figure 1, le processeur ne communique pas lui-même avec les composants périphériques car cela lui demanderait de connaître leurs spécificités respectives. Il délègue cette tâche à des contrôleurs (figure 1), chaque contrôleur étant spécialement conçu pour s’occuper d’un type de périphérique précis (figure 1).
Outre le processeur, le composant indispensable à tout ordinateur est la mémoire (figure 1) : l’espace de sauvegarde où le processeur et, plus exactement, les programmes qui en reçoivent le contrôle, placent temporairement les informations avec lesquelles ils sont en train de travailler. Ils la privilégient par rapport au disque dur parce qu’elle est beaucoup plus facile et rapide d’accès (figure 1).
Elle a cependant deux inconvénients que le disque dur n’a pas : (1) l’espace disponible est relativement réduit ; et (2) dès qu’un programme termine (par exemple, parce qu’il n’a plus aucune instruction à exécuter, parce qu’une erreur s’est produite, ou parce que l’utilisateur a décidé de l’arrêter), toutes les informations qu’il a mises dans la mémoire sont automatiquement « nettoyées », c.-à-d. supprimées. S’il ne les a pas transférées vers le disque dur ou un composant équivalent, elles sont définitivement perdues.
De tout ce que nous venons de dire, un programmeur, ou tout au moins quelqu’un qui projette de le devenir, a besoin de retenir les points suivants :
- Programmer c’est donner des instructions au processeur ; un programme est une séquence d’instructions.
- Quand il lance notre programme, l’utilisateur de l’ordinateur nous donne momentanément le contrôle du processeur. De ce fait :
- nous bénéficions de toute sa puissance de calcul ;
- les contrôleurs acheminent vers nous les informations qu’obtiennent les composants périphériques d’entrée ;
- par leur intermédiaire, nous avons la possibilité de transmettre des informations aux composants périphériques de sortie ;
- nous pouvons sauvegarder des informations dans la mémoire facilement et rapidement, mais nous les perdrons si nous oublions de les écrire également dans un composant périphérique d’entrée-sortie capable de sauvegardes permanentes comme le disque dur.
La mémoire est constituée de cellules numérotées (figure 2). Le numéro d’une cellule est appelé son adresse car c’est grâce à lui que les programmes savent où se trouvent les informations qu’ils ont mémorisées (Tanembaum, , p. 70).
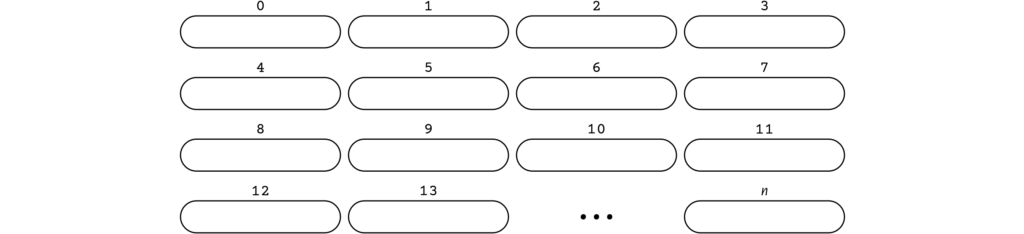
Un concept est primitif pour un ordinateur quand chaque cellule de sa mémoire peut en accueillir une instance.
Lorsque les composants d’un ordinateur s’échangent des informations (figure 1), ils se les envoient sous forme de signaux. Toutes les communications se font avec seulement deux signaux connus sous le nom de bits : le signal 0 et le signal 1. Les flèches vertes sur la figure 1 doivent être vues comme des flux de 0 et 1 ; le rôle de la mémoire est d’enregistrer des séquences de 0 et 1.
Il fut un temps où le nombre de 0 et 1 qu’une cellule mémoire pouvait contenir variait d’un ordinateur à l’autre (tableau 3). Mais de nos jours, tous les ordinateurs fonctionnent avec des cellules mémoires de huit bits (figure 4).
| Ordinateur | Date de sortie | Bits/cellule |
| Honeywell 6180 | 1963 | 36 |
| CDC 3600 | 1963 | 48 |
| Electrologica X8 | 1964 | 27 |
| DEC PDP-8 | 1965 | 12 |
| IBM 1130 | 1965 | 16 |
| SDS 940 | 1966 | 24 |
| CDC Cyber 70 | 1970–1980 | 60 |
| DEC PDP-15 | 1970 | 18 |
| XDS Sigma 9 | 1971 | 32 |
| Burroughs B1700 | ≈1972 | 1 |
| IBM PC | 1981 | 8 |
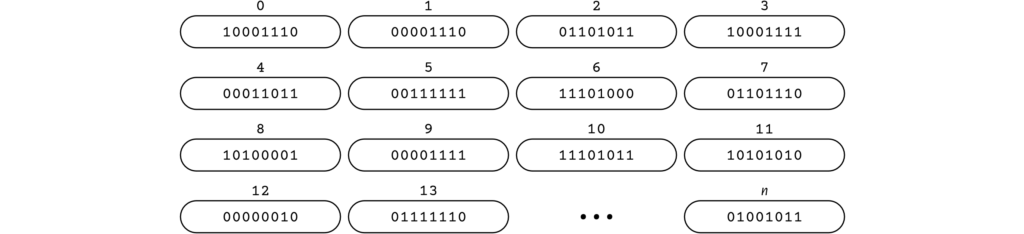
Comme la séquence de huit bits est devenue la norme, on lui a donné un nom : l’octet. Et puisque les concepts primitifs d’un ordinateur sont ceux dont les instances peuvent être placées dans une cellule de sa mémoire, alors il nous faut admettre que l’octet est le seul concept primitif des ordinateurs contemporains.
Les ordinateurs virtuels
Pourtant, les langages de programmation modernes nous donnent l’impression que l’ordinateur maîtrise les notions de booléens, d’entiers, de réels et de chaînes de caractères de façon innée. Jetez un œil aux instructions ci-dessous. Elles sont adressées au processeur en JavaScript (un des langages que nous apprendrons) :
let cellule1; cellule1 = 2020; cellule1 = "Voilà !"; cellule1 = false; let cellule2 = 3.14; cellule2 = true;
Fragment de code 5 — Exemple de programme écrit en JavaScript.
Ces instructions demandent au processeur de réaliser les actions suivantes :
- réserver quelque part dans la mémoire, à une adresse quelconque, une cellule à laquelle on fera ultérieurement référence sous le nom de
cellule1(ligne 1, figure 6.1) ; - mettre dans cette cellule l’entier 2020 (ligne 2, figure 6.2) ;
- remplacer consécutivement son contenu par la chaîne de caractères
"Voilà !"(ligne 3, figure 6.3) puis par le booléenfalse(ligne 4, figure 6.4) ; - réserver quelque part dans la mémoire, à une adresse quelconque différente de celle de
cellule1, une autre cellulecellule2initialisée avec le réel 3,14 (ligne 6, figure 6.5) ; - remplacer ce 3,14 par le booléen
true(ligne 7, figure 6.6).

Quand on regarde ce programme, ce qui est frappant, c’est que l’impossible semble être devenu possible : normalement, à l’intérieur d’une cellule mémoire il ne peut pas y avoir autre chose qu’un octet, mais JavaScript semble s’affranchir de cette règle.
En fait, il y a plusieurs niveaux de langages de programmation.
Le processseur, par exemple, a son propre langage de programmation : le langage machine ; un langage où les instructions sont des enchaînements de 0 et 1 (fragment de code 7). C’est le langage de plus bas niveau.
11100011101000000001011111100100 11100101100000000001000000000000
Fragment de code 7 — Exemple de programme écrit en langage machine.
Quand on programme en langage machine, ce sont bel et bien des cellules mémoires d’un octet que l’on manipule. Un processeur ARM Cortex-A7 MPCore (photo 8) va par exemple décoder le fragment de code 7 comme étant l’ordre d’écrire les quatre octets 00000000, 00000000, 00000111 et 11100100 dans quatre cellules mémoires adjacentes, un octet par cellule. Les experts de l’architecture ARMv7-A et de son langage d’assemblage (Arm, ) reconnaîtront les instructions mov r1, #2020 (Arm, , p. 485) et str r1, [r0] (Arm, , p. 675).

Le langage machine n’est pas le même pour tous les processeurs : un même code machine n’est pas forcément interprété de la même manière d’un processeur à l’autre. Personne ne peut dire ce que fait le programme du fragment de code 7 si on lui cache l’identité du processeur qui l’exécute.
Le langage machine facilite beaucoup le travail des fabricants de processeurs car pour le lire leurs produits n’ont besoin que de savoir différencier électroniquement le signal 0 du signal 1. Il complique par contre énormément la vie des programmeurs. C’est pour cette raison qu’ils se sont mis à inventer des langages de haut niveau comme JavaScript. On considère qu’un langage de programmation L est de plus haut niveau qu’un autre langage de programmation P si, grâce à L, le programmeur n’a plus besoin de se préoccuper de certaines contraintes de programmation imposées par P.
En montant en niveau, un langage présente en général l’ordinateur sous un nouveau visage : il change notre perception de son processeur, de sa mémoire ou de ses composants périphériques afin de les faire apparaître plus agréable à programmer. La vision déformée mais pratique qu’il nous en donne est qualifiée de virtuelle (Tanembaum, , p. 3), par opposition à la réalité moins plaisante qu’est l’ordinateur physique.
JavaScript nous propose par exemple d’oublier l’ordinateur physique et ses cellules mémoires d’un octet (figure 4), et de programmer à la place un ordinateur virtuel où les booléens, les entiers, les réels et les chaînes de caractères sont des concepts primitifs (fragment de code 5, figure 6).
Pour que nos programmes restent exécutables par l’ordinateur physique, JavaScript se charge pour nous de lui expliquer en langage machine (fragment de code 7) la signification de chacune des instructions de haut niveau qu’ils contiennent (fragment de code 5, figure 6), et d’encoder — c.-à-d. de convertir — dans le même temps en octets (figure 4) tous les concepts de haut niveau dont ils font usage (fragment de code 5, figure 6).
C’est l’existence d’ordinateurs virtuels comme celui de JavaScript, où les booléens, les entiers, les réels et les chaînes de caractères sont disponibles, qui nous permet de dire que l’ordinateur connaît ces concepts.
Pour les trois prochains articles, nous vous proposons d’étudier les principales méthodes d’encodage en octets des booléens, des entiers, des réels et des chaînes de caractères ; en particulier celles appliquées par JavaScript. Par contre, assurez-vous d’avoir une calculatrice, parce qu’on va être obligé de faire un peu de maths.
Questions
Pourquoi l’octet est-il devenu la norme en matière de taille des cellules mémoires ?
Citations
Il y a un grand fossé entre ce qui est commode pour nous et ce qui est commode pour l’ordinateur. Les gens souhaitent s’en servir pour faire X, mais l’ordinateur ne sait faire que Y. C’est problématique. […]
Le problème se résout de deux manières. L’idée de base est d’inventer un nouveau jeu d’instructions plus proche des besoins des gens que le jeu d’instructions offert par la machine. L’ensemble de ces nouvelles instructions forme un langage que nous nommerons L1, tout comme les instructions intégrées dans la machine forment un langage L0. Les deux approches diffèrent sur la méthode par laquelle elles permettent aux programmes codés en L1 de tourner sur l’ordinateur alors que ce dernier ne comprend que les programmes écrits en langage machine L0.
La première consiste à remplacer chaque instruction du programme en L1 par une séquence équivalente d’instructions disponibles en L0. Le résultat est un programme entièrement en L0 que l’ordinateur va exécuter en lieu et place de l’original en L1. Cette technique s’appelle la traduction.
L’autre approche est de créer un programme en L0 capable de décoder l’une après l’autre les instructions contenues dans les programmes en L1, et d’exécuter immédiatement à la volée les séquences d’instructions équivalentes en L0. La nécessité de produire une version en L0 des programmes en L1 est supprimée. Cette technique s’appelle l’interprétation, et le programme qui fait ce travail, un interprète.
La traduction et l’interprétation sont similaires. Dans les deux cas, l’exécution par l’ordinateur des instructions en L1 est rendue possible par l’existence d’instructions équivalentes en L0. La différence, c’est qu’avec la traduction, le programme en L1 est entièrement converti en L0, puis mis de côté au profit du nouveau programme obtenu, qui est chargé dans la mémoire à sa place, et à qui est donné le contrôle de la machine.
Avec l’interprétation, chaque instruction en L1 est examinée, décodée, et exécutée sur-le-champ. Aucun programme n’est généré. Cette fois, c’est l’interprète qui est aux commandes. Le programme en L1 n’est pour lui qu’une donnée d’entrée. Les deux approches sont largement utilisées, et on a de plus en plus tendance à les combiner.
Cela dit, au lieu de penser en termes de traduction et d’interprétation, il est souvent plus simple de s’imaginer en présence d’un ordinateur fictif, d’une machine virtuelle programmable directement en L1. […] Si une telle machine pouvait être construite à bon marché, nous pourrions complètement nous passer du langage L0 et des ordinateurs qui le supportent. Nous n’aurions en effet qu’à créer nos programmes en L1 et à profiter d’elle pour les exécuter. Hélas ! cette machine est généralement trop chère ou trop compliquée à fabriquer avec des circuits électroniques. Cela ne nous empêche pas toutefois de préparer pour elle des programmes comme si elle existait, étant donné que les ordinateurs physiques sont en mesure de les exécuter après traduction ou interprétation en L0.
Pour faciliter la traduction et l’interprétation, les langages L0 et L1 ne doivent pas être « trop » différents. À cause de cela, la plupart des développeurs ne seront probablement toujours pas satisfaits par L1, même s’ils le trouveront certainement meilleur que L0. Ce constat peut sembler décourageant quand on se souvient que le but premier pour lequel L1 a été inventé est de libérer le programmeur de la contrainte d’avoir à exprimer ses algorithmes dans un langage plus adapté aux machines qu’à ses besoins. Heureusement, la situation n’est pas sans espoir.
La solution évidente est de concevoir un troisième jeu d’instructions encore plus distant de l’ordinateur que L1, et qui tient encore mieux compte des problèmes que les gens cherchent à résoudre. Ce troisième jeu d’instructions forme lui aussi un langage que nous appellerons L2 […]. Nous pouvons écrire nos programmes en L2 comme si une machine supportant le L2 existait. Pour les exécuter, il nous suffira de les traduire en L1 ou de les faire exécuter par un interprète codé en L1.
L’invention successive de nouveaux langages, chacun plus commode que son prédécesseur, peut continuer indéfiniment jusqu’à ce que quelqu’un finisse par créer un langage adéquat.
Bibliographie
Arm. ARM Architecture Reference Manual. ARMv7-A and ARMv7-R edition. . Disponible en ligne sur Arm Developer — dernier accès le .
Knuth, Donald E. « Computer Science and its Relation to Mathematics. » Dans Selected Papers on Computer Science. Stanford, California : Center for the Study of Language and Information, . Copublié par Cambridge University Press.
Tanembaum, Andrew. Structured Computer Organization. 5e éd. Upper Saddle River, New Jersey : Pearson Education, Inc., .
Crédits photographiques
bohed (nom d’utilisateur sur Pixabay). ‹Disque dur.› . Disponible en ligne sur Pixabay (numéro de référence : 607461) — dernier accès le . Photo utilisée sur la figure 1.
Damian Patkowski (nom d’utilisateur sur Unsplash). ‹iMac.› . Disponible en ligne sur Unsplash — dernier accès le . Photo utilisée sur la figure 1.
geralt (nom d’utilisateur sur Pixabay). ‹Clavier d’ordinateur.› . Disponible en ligne sur Pixabay (numéro de référence : 70506) — dernier accès le . Photo utilisée sur la figure 1.
Hans (nom d’utilisateur sur Pixabay). ‹Souris d’ordinateur.› . Disponible en ligne sur Pixabay (numéro de référence : 236901) — dernier accès le . Photo utilisée sur la figure 1.
Martinelle (nom d’utilisateur sur Pixabay). ‹Cables ethernet.› . Disponible en ligne sur Pixabay (numéro de référence : 1572617) — dernier accès le . Photo utilisée sur la figure 1.
NonChanon (nom d’utilisateur sur iStockphoto). ‹Bureau au style rétro.› . Disponible en ligne sur iStockphoto (numéro de référence : 636728176) — dernier accès le . Photo mise en avant.
Pexels (nom d’utilisateur sur Pixabay). ‹Ordinateur portable Apple.› . Disponible en ligne sur Pixabay (numéro de référence : 1846666) — dernier accès le . Photo utilisée sur la figure 1.
Raimond Spekking (nom d’utilisateur sur Wikimedia Commons). ‹Processeur quadricœur ARM Cortex-A7 MPCore d’un Wiko Rainbow 4G.› . Disponible en ligne sur Wikimedia Commons — dernier accès le . Photo 8.
{kind=link}
skeeze (nom d’utilisateur sur Pixabay). ‹Mémoires d’ordinateur.› . Disponible en ligne sur Pixabay (numéro de référence : 857098) — dernier accès le . Photo utilisée sur la figure 1.
Slejven Djurakovic (nom d’utilisateur sur Unsplash). ‹Processeur.› . Disponible en ligne sur Unsplash — dernier accès le . Photo utilisée sur la figure 1.